3
Chapter 8: Getting More Fiber
I searched google images for “are you getting enough fiber” and this was the first image to come up. I love this rabbit so much that I just had to make him the face of my fiber system. credit: http://healthcoachdrew.com

Disclaimer: I do not work for Sony. Despite the disturbing percentage of my shirts, jackets, and bookbags that are PlayStation dev-related, I have never worked for Sony. I do, however, have many friends that work at Sony, some of which I hope will call off the corporate lawyers. JayStation is in no way associated with Sony or PlayStation, and any stupid things I say represent only my own ineptitude and silliness.
On the road to threads and schedulers, we’ll make a quick stop in fibertown. Many of you should be familiar with fibers from Sony’s libfiber, or you might know them as microthreads as they are called in some scripting languages. They are basically lightweight user-switchable threads, and are great for hiding latency in such a way as you don’t have to worry as much about thread safety. Their superpower is that they allow you to run some code, yield, and then continue exactly where you left off, as opposed to other types of functions that must run to completion.
A fiber scheduler is just a list of fibers, and a fiber is nothing more than a saved context, holding the value of some GPRs and maybe even some coprocessor registers like NEON. In this sample, my context holds the following information:
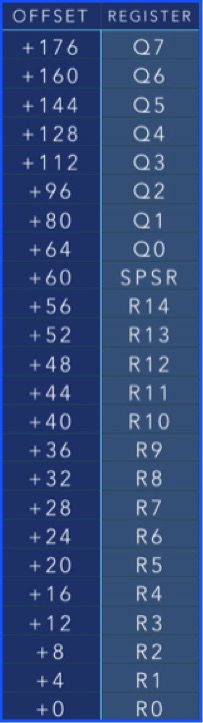
This is the context I am currently saving for my fibers. We are saving GPRs r0 through r14 (but not r15), the process status register, and the NEON coprocessor registers. r15 is the program counter, and it is not something we want to restore, as doing that would immediately jump out of our yield function before we clean up. Instead, we’ll just restore the link register (r14) and then mov pc, lr at the end of our yield. q0 through q7 are the NEON vector registers.
So in this example, each context is 192 bytes, and for every fiber we have, there must be a 192 byte context storage area. Fibers, like threads, also require their own stack space. Most sane APIs have the user allocate the stack area and pass it as well as the stack size to the fiber creation function. However, for test purposes, its acceptable to do something like this
.equ NUM_GPRS_TO_SAVE, 16
.equ NUM_GPRS_TO_SAVE_SIZE, (NUM_GPRS_TO_SAVE * 4)
.equ NUM_VGPRS_TO_SAVE, 8
.equ NUM_VGPRS_TO_SAVE_SIZE, (NUM_VGPRS_TO_SAVE * 16)
.equ TASK_CONTEXT_SIZE,(NUM_GPRS_TO_SAVE_SIZE + NUM_VGPRS_TO_SAVE_SIZE)
.equ MAX_OS_TASKS, 4
.equ TOTAL_TASK_CONTEXT_SIZE, (TASK_CONTEXT_SIZE * MAX_OS_TASKS)
.equ TASK_STACK_SIZE, (1024)
.equ TOTAL_TASK_STACK_SIZE, (TASK_STACK_SIZE * MAX_OS_TASKS)
.section .data
.ALIGN 2
num_tasks: .word 0
current_task: .word 0
.align 6 // ctx size is multiple of cacheline size, starts on boundary
task_context_area: .space TOTAL_TASK_CONTEXT_SIZE
.align 6
task_stack_area: .space TOTAL_TASK_STACK_SIZE
////////////////////////////////////////////////////////////////
// js2osTaskAdd: add a task to the OS task list
// input:
// r0 - address of function to run
// r1 - some void ptr to data
// note: for the time being, not thread safe. You can add tasks
// from multiple threads but not if the task scheduler is already
// running
////////////////////////////////////////////////////////////////
.globl js2osTaskAdd
js2osTaskAdd:
push {lr}
push {r0, r1}
// increment the task count
mov32 r1, num_tasks
ldr r2, [r1]
add r3, r2, #1
cmp r3, #MAX_OS_TASKS
bgt js2osTaskAdd_too_many_tasks
str r3, [r1]
// at this point the current task num (zero-based) is in r2
// now we have to get the stack and context area for this task
// at the end of it all r0 is stack address, r2 is task num, r3 is context addr
mov r0, r2
bl js2osTaskGetContextStart
mov r3, r0
mov r0, r2
bl js2osTaskGetStackStart
// store out the values we care about: lr (task func), r0 (void *data), r13 (stack ptr), and r1 (task num)
str r0, [r3, #52]
pop {r0, r1}
str r0, [r3, #56]
str r1, [r3, #0]
str r2, [r3, #4]
js2osTaskAdd_too_many_tasks:
pop {pc}
////////////////////////////////////////////////////////////////
// js2osTaskYield: switch tasks
// can only be called from a task
// save current task state and switch to a new task
////////////////////////////////////////////////////////////////
.globl js2osTaskYield
js2osTaskYield:
// save out the current task state
// save these because r0, r1, lr are modified by js2osTaskGetContextStart
push {r0}
push {r1,lr}
// get the current task context ptr into r0
mov32 r0, current_task
ldr r0, [r0]
bl js2osTaskGetContextStart
// save the status register
mrs r1, cpsr
str r1, [r0, #60]
pop {r1,lr}
// store out the context without r0 (we're using it for context address)
add sp, sp, #4
stmib r0, {r1-r14}
sub sp, sp, #4
// now we store the correct r0 (which we pop into r1 lolz)
pop {r1}
str r1, [r0]
// now we store out the NEON regs. I think this can be done lazily
// with an invalid instruction exception, but I'm doing it manually
add r0, r0, #NUM_GPRS_TO_SAVE_SIZE
vstmia r0, {q0-q7}
// increment task number
mov32 r2, current_task
mov32 r1, num_tasks
ldr r0, [r2]
ldr r1, [r1]
add r0, r0, #1
cmp r0, r1
movge r0, #0
str r0, [r2]
// load the next task state
bl js2osTaskGetContextStart
// restore NEON regs
add r1, r0, #NUM_GPRS_TO_SAVE_SIZE
vldmia r1, {q0-q7}
// restore the status register
ldr r2, [r0, #60]
msr cpsr, r2
// restore the GPRs
ldmia r0, {r0-r14}
mov pc, lr
The two main functions that will make up our task system are task creation, and task switching. Task adding is simple, and looks like this:
That first part just increments the number of added tasks, an obviously important bit of information to the thing cycling through tasks. Next, because we need to know where to initialize the context registers, we get the start of the context area for the fiber we are adding. js2osTaskGetContextStart takes in a task number (zero-based) in r0 and returns the context address in r0. js2osGetStackStart does the same thing for the task stack, except that it adjusts the pointer for the fact that the stack starts at the end of the memory block and grows down. Finally with the context pointer in r3, and the fiber stack pointer moved to r0, we start filling in the context. In order, we are:
0) writing the task stack pointer (r0) to context addr + 52 (r13, aka SP)
1)restoring the function address and data address in r0 and r1 respectively
2)writing the function address (r0) to context addr + 56 (r14, aka LR)
3)writing the user data void ptr (r1) to context addr + 0 (r0)
4)writing the current fiber number (r2) to context addr + 4 (r1)
TL;DR: on fiber switch we jump to the LR address (user supplied fiber function) with the user data pointer in r0 and the fiber number in r1. That brings us to the most fun part: switching fibers.
I’m being a little sloppy here, so please bear with me. We want to get the context address for the currently running task, and write the register state to it. But to do this we need to push r0, use it as a scratch register for storing the task context start address, and then pop and save the real r0 later.
stmib stands for store multiple increment before. Remember our task pointer context points to the location we save r0, but we don’t want to save r0 right now. stmib pre-increments the write address by 4 bytes, meaning it starts writing to the place where r1 gets stored, and then writes out GPRs r1 through r14 to the context area. At the time we do this, r0 is still pushed on the stack meaning the stack pointer is 4 bytes too low. That add sp, sp, #4 allows us to store the correct stack pointer to the context, and the sub sp, sp, #4 restores it allowing us to pop r0 off the stack. Because I want to confuse you (and because r0 is being used as the context address) I pop r0’s value into r1, and then proceed to save r0 (errr... or do I mean r1?) to the context. Finally we increment r0 to the start of the area we save NEON registers, and write those out. vstmia is vector store multiple increment after, and allows us to save out the NEON vector registers q0 through q7.
Finally we increment the current task number to get the next task, wrapping around if need be. We get the address of that task’s context and use it to restore the saved registers with ldmia (load multiple increment after, as you can probably guess by now).
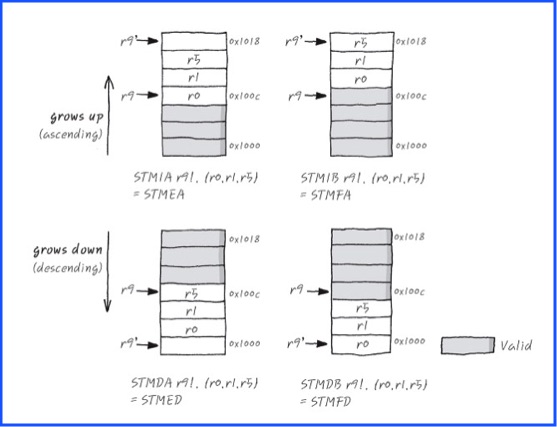
And before I go, I just wanted to further clarify the meaning of increment after, increment before, decrement after, and decrement before in those store multiple instructions. They refer to what happens when each register is written. For example
increment before will increment the write pointer by 4, write a register, increment by 4, write the next register...
increment after will write a register, increment the write pointer by 4, write the next register, increment by 4...
decrement before will decrement the write pointer by 4, write a register, decrement by 4, write the next register...
decrement after will write a register, decrement the write pointer by 4, write the next register, decrement by 4...
Here is an awesome image I found on google images that really hammers it home (credit: http://egloos.zum.com/recipes/v/5059742)
Errata: nothing like the pressure of sharing your code with the world to help you see your own errors. The bit saving the process status register seems to be using SPSR, a relic from an experiment where tasks switched automatically via timer IRQ interrupt. I will fix that as soon as possible