一所懸命HW設計者のふりをやっとる現代のC++が大嫌いなSWの開発者。
FPGAのGPUと家庭用ゲーム機の設計、うちの猫(ニュートリノ+コスモス)、百人一首、競技かるた、お箏の演奏、ゲーム開発、抹茶+和菓子
投稿は私個人の意見で、会社を代表するものやない
Rainy days always remind me of summers at my grandmother’s farm in the Catskills, spending lazy days floating on the lake, laptop in hand, pipelining SPU asm loops until there were no more empty slots in the schedule to fill. Those days were pretty great. But do you know what’s not so great? Journalists blindly repeating the SPUs were difficult to program without any real understanding of the nuanced details. Not cool.
In this post I am going to attempt to give a Fair And Balanced1, unbiased2, and nuanced (笑) description of what people usually mean when they complain about various aspects of the SPUs. The goal is to keep it nontechnical enough for humans to understand, while providing enough details to capture nuance beyond the usual generalisations. I will fail at both goals
As always, this post is constantly changing as I get ideas/feedback from the Smart Kidz. Please feel free to share this with a games journalist you love!
Problem 1: A Changing Industry
Timing is everything. That’s going to be common theme here. The industry was a very different place when I joined in the PS2 era. Games were smaller, they were often made with only a handful of programmers, and you tended to target one platform, and then worry about ports later. Consoles had really weird/creative/wonderfully fascinating custom architectures, and it wasn’t unheard of for all programmers on a team to be low level wizards, who studied hardware manuals, and dreamed of ways to abuse weird bits of hardware to do things it probably wasn’t meant to do.
Games were already starting to get bigger during the PS2 era, due to the switch from CD to DVD, but this really accelerated on PS3 with Blu-Ray, a 8x increase in CPU DRAM, and a 64x jump in video memory. Not only were games were getting bigger, but budgets were getting bigger, and with that, team sizes started exploding. Targeting multiple consoles was becoming more common, and suddenly more people were specialising in very specific disciplines, so you could no longer assume that all devs were assembly wizards that sat around reading and memorising hardware manuals.
In so many ways, the PS3 felt like a radical jump into the future, while simultaneously feeling like a relic of PS2-era thinking. Old skool hardware experts could achieve unfathomably magical things on it’s custom architecture, but for larger teams targeting multiple platforms who didn’t have the time or resources to put in the necessary work, the result was often leading on Xenon and producing low quality PS3 ports as an afterthought. This was sad, because as I will cover later, leading on PS3 often resulted in much petter performance on Xenon as well!
Problem 2: Hanging On By A Thread
The youngsters amongst us may not know this, but games used to be single threaded. I mean some libraries and services might have been running on a thread, but in general your game had one thread, all the work was done there, and life was simple. There was no thought put in to how to break up work into jobs, and no one was thinking too intensely about specifically designing data to be multithread-safe.
That all started to change with the PS3 generation. Xenon had three PPC cores with two HW threads each, and the PS3 featured 6.5 usable SPUs, ridiculously fast vector processors. On both PS3 and Xenon, teams that had zero experience with multithreading suddenly had to grapple with how to jobify their code, and how to share data from multiple threads at the same time without causing corruption. Before you could just write a function and call it from somewhere, but now every thing you wanted to add suddenly required far more thought, and involved alot more senior people making decisions.
This is another example of bad timing. The multithreaded transition was pretty rough for many teams. Entire engines had to be updated, many people had to skill up, and countless years of tracking down very rare crashes ensued. Now we just kind of take for granted that everything should be jobified and multithread safe, but back in the PS3 era all these things were very new problems, and I think the PS3 tends to take an unfair share of the blame for this eventually necessary transition.
Problem 3: Stay In Your Lane
The SPUs were 4-way SIMD machines. SIMD means Single Instruction Multiple Data, and basically meant you could do a single instruction (add, subtract, multiply, etc) on a vector of four numbers at once. Cool, right?
Here’s an example. Adding {0, 1, 2, 3} together with {4, 5, 6, 7} would result in {0+4, 1+5, 2+6, 3+7}, or {4, 6, 8, 10}. Being able to do these four adds at once sounds super useful for video games where you might have a million particles flying around and you need to add velocities to change the particle positions.
Now lets try a different operation. Let’s say we have two vectors, {A, B, C, D} and {E, F, G, H}, and we want to do A x E + B x F + C x G + D x H. Well, that should be easy. We can start off by multiplying the two vectors together giving {A x E, B x F, C x G, D x H}, but now we are stuck. There are no instructions that allow operations across different lanes of the same vector. In other words, if we have {0, 1, 2 ,3} there is no way to get a single number 0+1+2+3 🙁
Alright, there are a few options here. The easiest (and worst) option is to to put the number you care about in lane 0 of different vectors. Assuming X means don’t care, that’s
{0, X, X, X}
{1, X, X, X}
{2, X, X, X}
{3, X, X, X}
—————-
{6, X, X, X}
That will give you the right answer, but it will take three adds, and although instructions operate on four lanes of data, three of those lanes are garbage data that no one actually cares about. You’re operating at 25% of what the SPUs can really do!
The *real* solution to this involved transposing from something called AoS to something called SoA. I won’t get into the details here, but you either had to have your data already in SoA format, or you had to write SPU code to do the transpose. But SoA can be a little weird to wrap your head around if you’re not used to it, and poor Godai Gameplay-san just wants to get her code onto the SPUs without having to worry about weird transforms and transposed data formats
I’m not convinced this was a massive problem. Sure, for things that don’t vectorise well, it seems a bit wasteful to only use 25% of the things you calculate. But remember, even a naieve SPU implementation was usually a massive win, performance-wise. If you wanted to really fully utilise the HW, you needed to directly write assembly and worry about things like pipelining loops, balancing even and odd instructions, and vectorisation, but you could also write your code in a very high level language like C, and it would run just fine.
Fun optional trivia: The operation mentioned above is called the dot product, and its used in almost every area of gamedev, especially graphics. Microsoft recognised this and added an instruction that did a single dot product, but had trouble closing timing at their target clock, so they had to lengthen their pipeline by a few stages to ease things. PS3 didn’t have a specific dot product instruction, but by using SoA data format you could do four dot products in parallel, at much higher performance than Microsoft could reach. But what happens if you only needed one dot product? To answer that, I must quote Saint Acton of Insom: In video games, you never have just one of something. If you have one, you have a million
Problem 4: Shaders Before Shaders
I’m going to describe something, and you have to guess what I am talking about. I am writing programs that have to run on some bespoke bit of hardware, radically different than the CPU the main game runs on. I have to use a different toolchain to build a binary, load that binary at runtime, and then tell the other hardware how to run it. When crashes or problems happen, I can’t use the CPU debugger, but rather have to attach a totally different standalone tool that is a bit harder to use and lacks some of the convenience of the more mature CPU debugger built into the Visual Studio IDE.
If you’re young enough, it probably sounds like I am describing shaders. Shaders require adding an additional build step and a using different compiler to build, the shader binaries have to be loaded at runtime (or embedded in your elf), and you have to kick (dispatch) the GPU to run the shader. However, this workflow also applied to the SPUs, and was considered by some to be really cumbersome at the time. And while graphics programmers were somewhat used to this heterogeneous model from the PS2 days, on the PS3 it wasn’t just graphics programmers but gameplay programmers and physics programmers and pretty much everyone that needed their work to run on the SPUs.
This is yet another example where timing worked against the PS3. So much of what people used to consider annoying is now things they just accept when working with shaders. But much like how Tandy invented the iPhone in 1982, you don’t get any points for being too far ahead of the times
{kind=link}
Problem 5: A Trip To The Local Store
I saved the most serious for last. I think that out of all the people I have talked to, complaints about the 256KB local store come up the most.
First a little bit about why the SPUs are the way they are. Originally specced to run at 4GHz, they were relatively simple SIMD machines with in-order issue and a short pipeline (4 stages for even, 6 stages for odd). They were absolute monsters, and like any monster, they need to be well fed to be happy. All that data needed to come from somewhere, and the two options were shared DRAM or dedicated local static memory. DRAM was nice because it would have given the SPUs access to a giant (hundreds of megabytes!!) memory space, and because memory was shared, the SPUs could all work from the same memory, and easily share things with the CPU without copying things around.
There are two massive downsides to this. First, DRAM is extremely far away and very slow to access, so in cases where there aren’t enough unrelated instructions to keep the SPU busy while it waits for data to arrive from memory, you could end up wasting tens of thousands of cycles just waiting. The other downside is arbitration. Memory tends to have one read port, and that port needs to be shared/arbitrated between every client. So not only would each SPU be fighting the CPU to have its memory request selected, but the SPUs would also be fighting against each other. It was never going to work.
The other option was a static memory. These are implemented in transistors on the SoC itself, so they are extremely fast and extremely close, and would be used exclusively by one SPU. Think of it like the static memories used to implement CPU caches, but manually managed. The downside is that scaling these up is… difficult. Have a look at Goto-san’s images from https://pc.watch.impress.co.jp/docs/2007/0216/kaigai338.htm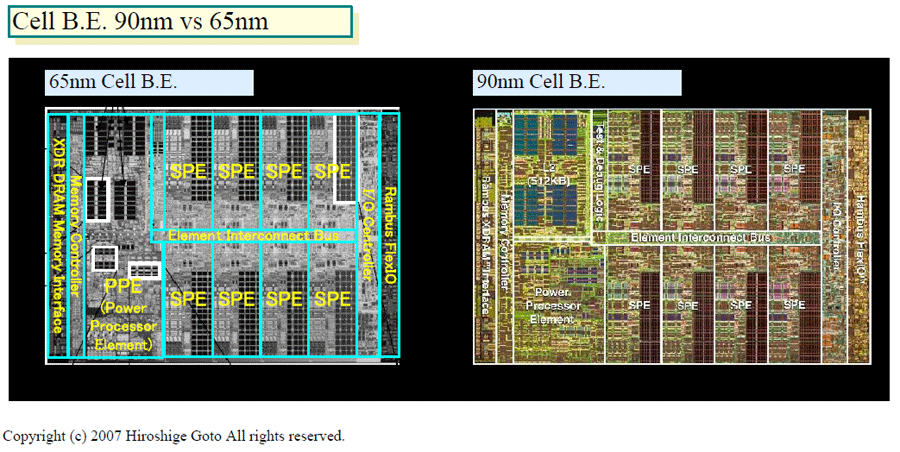

Even if you’re not a hardware designer, you can see what doubling the size of the local store would have done to chip size and cost, not to mention the effects on power, floorplan, routing, and a whole other host of physical design issues.
OK, so we are stuck with a 256KB static memory, but surely 256KB is enough for most uses! Let’s see, a 256×256 texture is 65,536 pixels, and if each pixel is 4 bytes, that’s… 100% of memory. Actually, because the local store also has to hold the SPU program you are running (and also maybe bits of a job kernel), that means we can’t even fit a tiny 256×256 texture in memory all at once. What can we do?
And this brings us to the number one complaint people have about SPU programming complexity. If you wanted to work on large textures, there was no way to have the whole texture in local store at once. However, you had a few options. The most basic was to divide up the texture into smaller tile pieces, and use DMA to copy the piece you need into local store. Working on smaller pieces one at a time made it easy to process large textures with minimal additional effort. The downside is that the SPUs sat around idly doing nothing while they waited for a new piece of the texture to arrive.
If you wanted to get fancy, you could double or triple buffer. The basic idea is that you could asynchronously copy memory around in the background via DMA. If you divided local store into two areas, A and B, it was possible to work on the texture piece in area A in parallel as the next piece was being copied to area B. You could then repeat this flipping back and forth between A and B until you did the whole texture. In practice, it was hard to get right, easy to mess up, and could be fairly complicated to debug, but it was the best way to work on large data sets. If you didn’t need the extra perf, you could do the simple single buffer mentioned previously and call it a day, no problems.
The clever among you are calling me out for my synthetic and not-so-realistic texture example. What if your algorithm was not so simple, and you couldn’t break the texture into tiles because you were randomly sampling all over the place? Well then you were screwed. Totally out of luck. This was easy on a shared memory system like Xenon, at a massive perf cost, but still doable. On PS3, the only option was to rework your algorithm, potentially at great cost, to something that can work on localized texture tiles
There is an upside, however! The Xenon CPU caches may not mandate spacial/temporal locality the way the PS3 did, but they sure did benefit from them. Leading on PS3, and using SPU-friendly spatially/temporally coherent algorithms, could also greatly improve performance on Xenon as well!
Miscellaneous Topics
TODO: add as I think of more things. C vs asm? Early state of the tools? Launching initially without SPURS? Misc thoughts on custom architectures? Even and Odd balancing? Summary?